Avant de poursuivre, il nous faut clarifier les concepts fondamentaux au fonctionnement d’un GAN. Commençons par expliquer ce qu’est le Machine Learning.
Un algorithme de Machine Learning est un ensemble de règles ou de processus utilisés par un système d’IA pour effectuer des tâches, le plus souvent pour découvrir de nouvelles informations et modèles de données, ou prédire les valeurs de sortie à partir d’un ensemble de variables d’entrée. Les algorithmes permettent au Machine Learning (ML) d’apprendre [1].
Le plus souvent, l’entraînement des algorithmes de ML sur un gros volume de données fournissent des réponses plus précises que sur une quantité moindre. À l’aide de méthodes statistiques, les algorithmes sont entraînés pour déterminer les classifications, obtenir des prédictions et découvrir des informations clés dans les projets d’exploration de données. Ces informations permettent d’améliorer les prises de décision pour stimuler les métriques de croissance.
Parmi les cas d’utilisation, les algorithmes de machine learning sont notamment employés dans l’analyse des données pour identifier les tendances et prévoir les problèmes avant qu’ils ne se produisent [2]. Les secteurs qui bénéficient particulièrement des algorithmes de machine learning pour la création de nouveaux contenus à partir de grandes quantités de données comprennent la gestion de la chaîne d’approvisionnement, les transports et la logistique, le commerce de détail et la fabrication. L’IA générative est largement adoptée dans ces secteurs pour sa capacité à automatiser les tâches, à améliorer l’efficacité et à fournir des informations précieuses, même pour les débutants. Voyons voir comment ces algorithmes fonctionnent.
Il existe 4 types d’algorithmes de Machine Learning : supervisés, non supervisés, semi-supervisés et par renforcement. Selon vos exigences en termes de budget, de vitesse et de niveau de précision, chaque type et variante a ses avantages. Les algorithmes de Machine Learning avancés nécessitent plusieurs technologies, notamment le Deep Learning, les réseaux neuronaux et le traitement du langage naturel. Ils peuvent utiliser l’apprentissage supervisé et non supervisé [3]. Un modèle d’apprentissage supervisé utilise des données d’entrée et de sortie étiquetées, alors qu’un modèle d’apprentissage non supervisé apprend à partir de données d’entraînement non-étiquetées. Celui qui nous intéresse particulièrement dans notre cas est l’algorithme d’apprentissage non-supervisé.
À la différence de l’apprentissage supervisé, l’apprentissage non supervisé est celui où l’algorithme doit opérer à partir d’exemples non annotés. En effet, dans ce cas de figure, l’apprentissage par la machine se fait de manière entièrement indépendante. Des données sont alors renseignées à la machine sans qu’on lui fournisse des exemples de résultats. Ainsi, dans cette situation d’apprentissage, les réponses que l’on veut trouver ne sont pas présentes dans les données fournies : l’algorithme utilise des données non étiquetées. On attend donc de la machine qu’elle crée elle-même les réponses grâce à différentes analyses et au classement des données.

Figure 1 - Différence entre apprentissage supervisé et apprentissage non-supervisé en IA (crédit : Balkiss.hamad – CC BY-SA 4.0)
Les modèles d’apprentissage non supervisé sont notamment utilisés pour le classement des données, le calcul approximatif de la densité de distribution et la réduction des dimensions. Son utilisation peut être réunie en problèmes de clustering et d’association [4, 5].
Un problème de clustering est un problème pour lequel on attend de la machine qu’elle rassemble sous forme de groupes (mise en cluster) des objets présents dans des groupes de données, et ce de la manière la plus juste et efficace possible. Cette technique, bien que parfois difficile à comprendre par l’homme, est très utilisée dans le domaine du marketing pour placer dans des groupes les différents clients par exemple. Un exemple d’algorithme très souvent utilisé dans le clustering est le K-means [6].
Le système d’association permet de trier et regrouper les données qui peuvent être liées grâce à certaines caractéristiques. Le but est donc de trouver des objets liés les uns aux autres sans qu’il s’agisse néanmoins d’objets identiques. À titre d’exemple, en fournissant à l’algorithme de nombreuses images de chats et d’accessoires pour chats, alors l’algorithme d’apprentissage non supervisé ne regrouperait pas tous les chats ensemble mais, par exemple, une pelote de laine avec un chat. Un exemple d’algorithme très souvent utilisé dans l’association est l’algorithme A-priori [7].
L’apprentissage non supervisé est très souvent utilisé dans le domaine de la reconnaissance vocale, comme pour l’utilisation de Siri ou Alexa notamment. Ainsi, ce dernier permet d’apprendre les particularités vocales du propriétaire du téléphone. De la même façon, certains téléphones portables l’utilisent pour disposer de manière automatisée les photos. En effet, le téléphone est apte à identifier la même personne sur des photos ou trouver des lieux afin de les ranger selon ces critères.
L’algorithme Minimax est un algorithme qui s’applique à la théorie des jeux [8]. Il s’agit d’une discipline théorique qui permet de comprendre (formellement) des situations dans lesquelles les joueurs, les preneurs de décision, interagissent. Un jeu est alors défini comme un univers dans lequel chaque preneur de décisions possède un ensemble d'actions possibles déterminé par les règles du jeu. Le résultat du jeu dépend alors conjointement des actions prises par chaque preneur de décision [9].
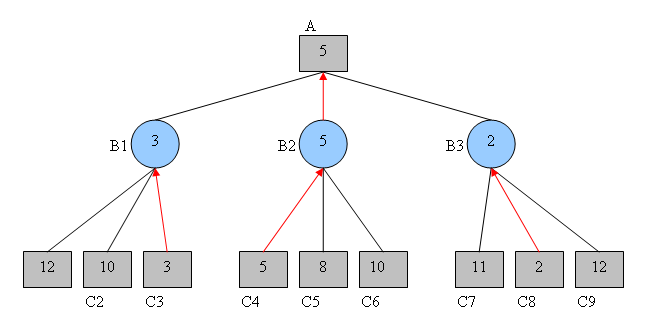
Figure 2 - Exemple de l'algorithme Minimax
Dans le schéma ci-dessus (Figure 2), les nœuds gris représentent les nœuds joueurs et les bleus les nœuds opposants. Pour déterminer la valeur du nœud A, on choisit la valeur maximum de l’ensemble des nœuds B (A est un nœud joueur). Il faut donc déterminer les valeurs des nœuds B qui reçoivent chacun la valeur minimum stockée dans leurs fils (les nœuds B sont opposants). Les nœuds C sont des feuilles, leur valeur peut donc être calculée par la fonction d’évaluation.
Les fondements mathématiques de ce domaine remontent aux années 1920 par Ernst Zermelo [10] et Émile Borel [11]. Par la suite, cette discipline s’est trouvée de nombreuses applications permettant notamment de comprendre des phénomènes économiques, politiques ou même biologiques. Parmi ces phénomènes, voici une liste de situations dans lesquelles la théorie des jeux peut être appliquée : la concurrence entre entreprises, la concurrence entre hommes politiques, un jury devant s'accorder sur un verdict, des animaux se battant pour une proie, la participation à une enchère, le vote d'un législateur soumis à la pression de lobbies, ou le rôle des menaces et des sanctions dans une relation à long terme.
Comme toute discipline théorique, la théorie des jeux consiste en une collection de modèles. Ces modèles sont alors des abstractions utilisées pour comprendre ce qui est observé ou vécu. Ils permettent de prédire l'évolution d'un jeu ou de conseiller le ou les joueurs sur le meilleur coup à jouer [12].
L'algorithme Minimax est destiné aux jeux à deux joueurs à somme nulle (et à information complète) consistant à minimiser la perte maximum (c'est-à-dire dans le pire des cas). Pour une vaste famille de jeux, le théorème du minimax de von Neumann assure l'existence d'un tel algorithme, même si dans la pratique il n'est souvent guère aisé de le trouver. Le jeu de Hex est un exemple où l'existence d'un tel algorithme est établie et montre que le premier joueur peut toujours gagner, sans pour autant que cette stratégie soit connue.
Il amène l'ordinateur à passer en revue toutes les possibilités pour un nombre limité de coups, et à leur assigner une valeur qui prend en compte les bénéfices pour le joueur et pour son adversaire. Le meilleur choix est alors celui qui minimise les pertes du joueur tout en supposant que l'adversaire cherche au contraire à les maximiser (le jeu est à somme nulle).
Désormais, présentons en quoi consistent les modèles génératifs. Tout d’abord, il existe 2 types de modèles : les modèles génératifs et discriminants. Il est essentiel de comprendre que les modèles génératifs et discriminants sont deux approches différentes qui sont largement étudiées dans la tâche de classification.
Le modèle discriminant a pour objectif de discriminer les différentes caractéristiques des données qu’on lui propose. Par exemple, en montrant au modèle un ensemble de tableaux, il devrait pouvoir distinguer les caractéristiques discriminantes de chacun des deux. C’est-à-dire le style, les couleurs, etc., avec, pour objectif final, de savoir si le tableau provient d'un artiste ou non.
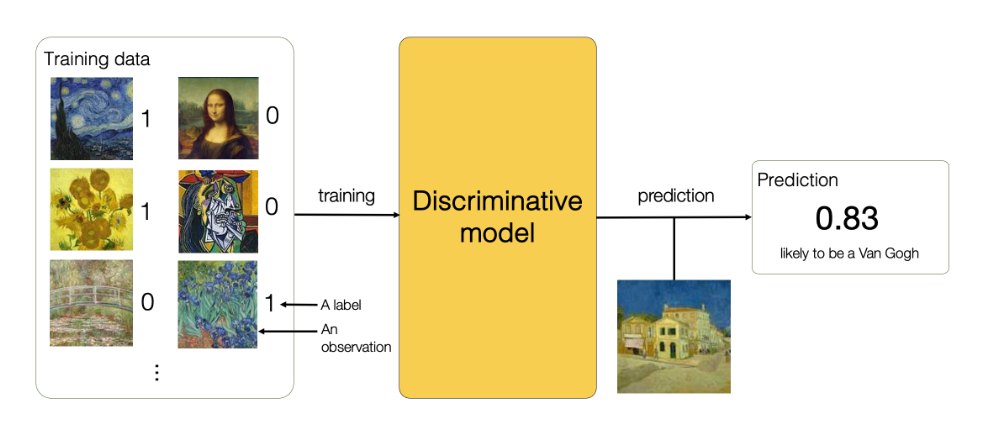
Figure 3 - Exemple de l'utilisation d'un modèle discriminant dans la classification de tableaux Van Gogh
Le modèle génératif, lui, distingue les différentes caractéristiques des données pour effectuer ensuite la tâche de classification. Par ailleurs, étant donné sa compréhension des caractéristiques, il est capable de les remettre en œuvre pour générer de nouvelles images. Pour l’illustrer, prenons des photos de chevaux. Notre modèle génératif va alors déterminer quelles sont leurs caractéristiques pour réaliser des images similaires, en réutilisant ces divers attributs.
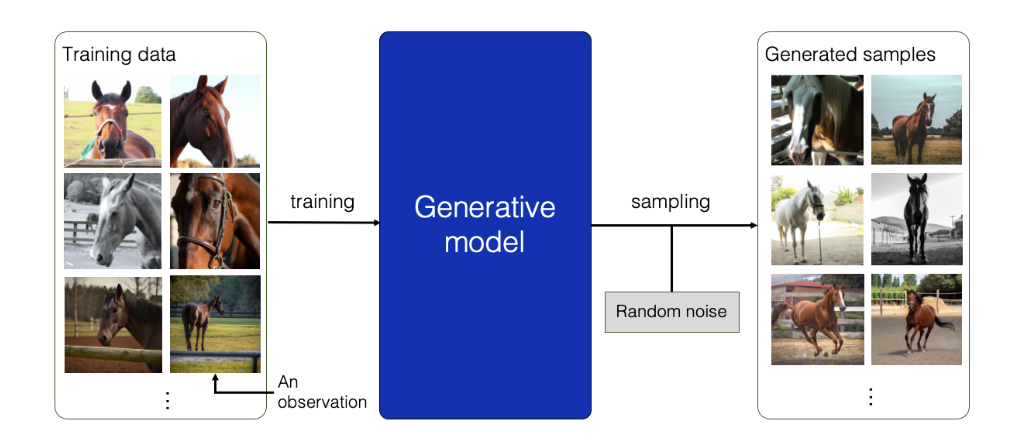
Figure 4 - Exemple de l'utilisation d'un modèle génératif pour générer des images de chevaux
Un modèle génératif peut, en finalité, générer une nouvelle image qui ressemble à l’une des images de classe qui lui ont été fournies pour la formation. Les modèles génératifs constituent alors l’une des approches les plus prometteuses pour atteindre cet objectif [13].
Maintenant, ce qui est fondamental dans les réseaux adverses génératifs est que les modèles discriminants et génératifs ne travaillent pas de concert mais s’affrontent. En effet, pendant le processus d'entraînement, ces deux entités sont en compétition, et c'est ce qui leur permet d'améliorer leurs comportements respectifs. C'est ce que l'on appelle la rétro-propagation, nous expliquerons cette notion par la suite.
L'objectif du générateur est de produire des outputs sans que l'on puisse déterminer s'ils sont faux, tandis que l'objectif du discriminateur est d'identifier les faux. Ainsi, au fil du processus, le générateur produit des outputs de meilleure qualité, tandis que le discriminateur détecte de mieux en mieux les faux. De ce fait, l'illusion est de plus en plus convaincante au fil du temps.
Dans un premier temps, il convient de déterminer ce que l'on souhaite que le GAN produise (l'output). La seconde étape consiste à composer un ensemble de données basé sur ces paramètres. Ces données sont ensuite entrées dans le générateur jusqu'à ce qu'il commence à produire des outputs convaincants.
Les images générées sont ensuite transmises au discriminateur, aux côtés des véritables points de données du dataset. Le discriminateur filtre les informations, et établit une probabilité comprise entre 0 et 1 pour déterminer l'authenticité de l'image. Le chiffre 1 signifie que l'image est réelle, le 0 indique qu'il s'agit d'un faux. Ces valeurs sont ensuite vérifiées manuellement, et le processus est répété jusqu'à ce que le résultat souhaité soit atteint [14].
Concrètement, l’apprentissage peut alors être modélisé comme un jeu à somme nulle en reprenant la notion de théorie des jeux. Un jeu à somme nulle est un jeu où la somme des gains et des pertes de tous les joueurs est égale à 0. Cela signifie donc que le gain de l’un constitue obligatoirement une perte pour l’autre [15].
Les systèmes d'apprentissage en profondeur sont capables d'apprendre des modèles extrêmement complexes, et ils y parviennent en ajustant leurs poids. Comment les poids d'un réseau de neurones profond sont-ils ajustés exactement ? Ils sont ajustés par un processus appelé rétro-propagation [16].
L’algorithme de rétro-propagation est probablement le bloc le plus important au sein d’un réseau de neurones. Il a été introduit dans les années 1960 et popularisé approximativement 30 ans plus tard, en 1989, par Rumelhart, Hinton et Williams dans l’article : « Learning representations by back-propagating errors » [17].
Commençons par définir l'objectif de la rétro-propagation. Les poids d'un réseau neuronal profond sont la force des connexions entre les unités d'un réseau neuronal. Lorsque le réseau neuronal est établi, des hypothèses sont faites sur la façon dont les unités d'une couche sont connectées aux couches qui lui sont jointes.
Au fur et à mesure que les données se déplacent dans le réseau neuronal, les pondérations sont calculées et des hypothèses sont formulées. Lorsque les données atteignent la couche finale du réseau, une prédiction est faite sur la façon dont les entités sont liées aux classes du jeu de données. La différence entre les valeurs prédites et les valeurs réelles est la perte/l'erreur, et l'objectif de la rétro-propagation est de réduire la perte [18]. Ceci est accompli en ajustant les pondérations du réseau, rendant les hypothèses plus proches des vraies relations entre les entités en entrée.
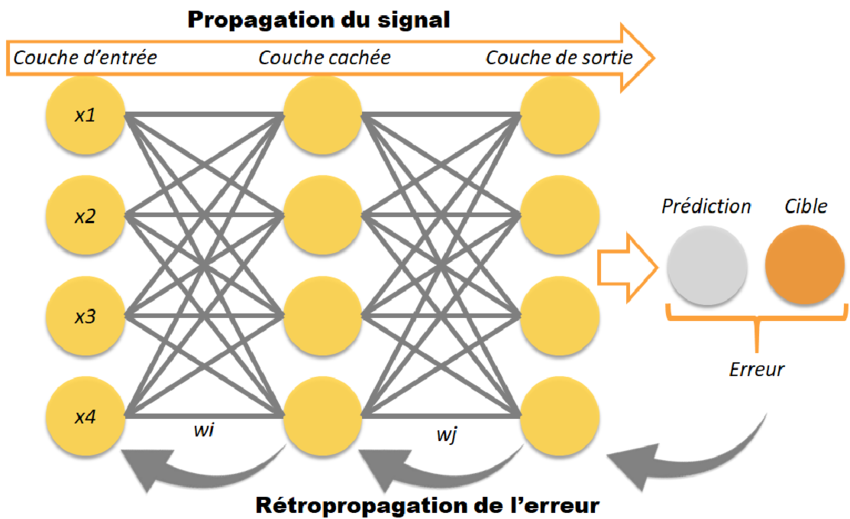
Figure 5 - Représentation de l'algorithme de rétropropagation du gradient de l'erreur
Avant que la rétro-propagation puisse être effectuée sur un Réseau neuronal [19], la passe d'entraînement régulière en avant d'un réseau de neurones doit être effectuée. Lorsqu'un réseau de neurones est créé, un ensemble de poids est initialisé. La valeur des pondérations sera modifiée au fur et à mesure que le réseau est formé. La passe d'entraînement vers l'avant d'un réseau de neurones peut être conçue comme trois étapes distinctes : l'activation des neurones, le transfert des neurones et la propagation vers l'avant.
Lors de la formation d'un réseau de neurones profonds, nous devons utiliser plusieurs fonctions mathématiques. Les neurones d'un réseau neuronal profond sont composés des données entrantes et d'une fonction d'activation qui détermine la valeur nécessaire pour activer le nœud. La valeur d'activation d'un neurone est calculée avec plusieurs composants, étant une somme pondérée des entrées.
Les poids et les valeurs d'entrée dépendent de l'index des nœuds utilisés pour calculer l'activation. Un autre nombre doit être pris en compte lors du calcul de la valeur d'activation, une valeur de biais. Les valeurs de biais ne fluctuent pas, elles ne sont donc pas multipliées avec le poids et les entrées, elles sont simplement ajoutées. Tout cela signifie que l'équation suivante pourrait être utilisée pour calculer la valeur d'activation :
Activation = somme (poids * entrée) + biais
Une fois le neurone activé, une fonction d'activation est utilisée pour déterminer quelle sera la sortie réelle du neurone. Différentes fonctions d'activation sont optimales pour différentes tâches d'apprentissage, mais les fonctions d'activation couramment utilisées incluent la fonction sigmoïde, la fonction Tanh et la fonction ReLU.
Une fois que les sorties du neurone sont calculées en exécutant la valeur d'activation via la fonction d'activation souhaitée, la propagation vers l'avant est effectuée. La propagation vers l'avant consiste simplement à prendre les sorties d'une couche et à en faire les entrées de la couche suivante. Les nouvelles entrées sont ensuite utilisées pour calculer les nouvelles fonctions d'activation, et la sortie de cette opération est transmise à la couche suivante. Ce processus se poursuit jusqu'à la fin du réseau de neurones.
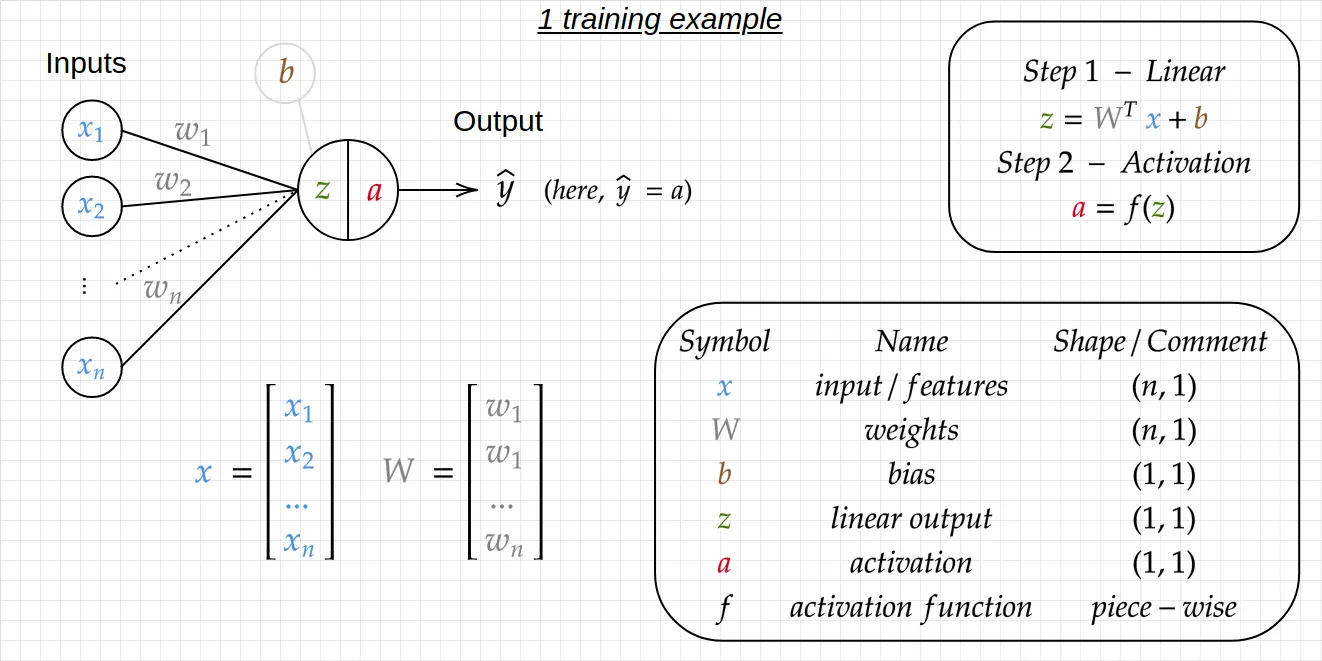
Figure 6 - Exemple d’un entraînement de Neurone artificiel
Le processus de rétro-propagation prend en compte les décisions finales de la passe d'entraînement d'un modèle, puis il détermine les erreurs dans ces décisions. Les erreurs sont calculées en comparant les sorties/décisions du réseau et les sorties attendues/souhaitées du réseau.
Une fois que les erreurs dans les décisions du réseau ont été calculées, ces informations sont rétro-propagées à travers le réseau, et les paramètres du réseau sont modifiés en cours de route. La méthode utilisée pour mettre à jour les poids du réseau est basée sur le calcul, en particulier sur la règle de la chaîne. Cependant, une compréhension du calcul n'est pas nécessaire pour comprendre l'idée derrière la rétro-propagation. Il suffit de savoir que lorsqu'une valeur de sortie est fournie par un neurone, la pente de la valeur de sortie est calculée avec une fonction de transfert, produisant une sortie dérivée. Lors de la rétro-propagation, l'erreur pour un neurone spécifique est calculée selon ce qui suit [20]:
erreur = (sortie_attendue – sortie_actuelle) * pente de la valeur de sortie du neurone
Lors d'une opération sur les neurones de la couche de sortie, la valeur de classe est utilisée comme valeur attendue. Une fois l'erreur calculée, l'erreur est utilisée comme entrée pour les neurones dans la couche cachée, ce qui signifie que l'erreur pour cette couche cachée est constituée à partir des erreurs pondérées des neurones trouvés dans la couche de sortie. Les calculs d'erreur remontent à travers le réseau le long du réseau de pondérations.
La descente de gradient1 est le processus de mise à jour des poids afin que le taux d'erreur diminue. La rétro-propagation est utilisée pour prédire la relation entre les paramètres du réseau de neurones et le taux d'erreur, qui configure le réseau pour la descente de gradient. La formation d'un réseau avec descente de gradient implique de calculer les poids par propagation vers l'avant, de rétro-propager l'erreur, puis de mettre à jour les poids du réseau [21].

{kind=link}