Un système de réseau antagoniste génératif (GAN) comprend deux réseaux neuronaux profonds : le réseau générateur et le réseau discriminateur. Comme nous l’avons vu, les deux réseaux s'entraînent dans un jeu contradictoire, où l'un essaie de générer de nouvelles données et l'autre tente de prédire si les résultats sont des données fausses ou réelles [1].
Techniquement, le GAN fonctionne comme suit. Une équation mathématique complexe constitue la base de l'ensemble du processus de calcul, mais il s'agit d'une vue d'ensemble simpliste :
Le générateur tente de maximiser la probabilité d'erreur du discriminateur, mais le discriminateur essaie de minimiser la probabilité d'erreur. Lors des itérations d'entraînement, le générateur et le discriminateur évoluent et se confrontent continuellement jusqu'à atteindre un état d'équilibre. Dans l'état d'équilibre, le discriminateur ne peut plus reconnaître les données synthétisées. À ce stade, le processus d'entraînement est terminé [1, 2].
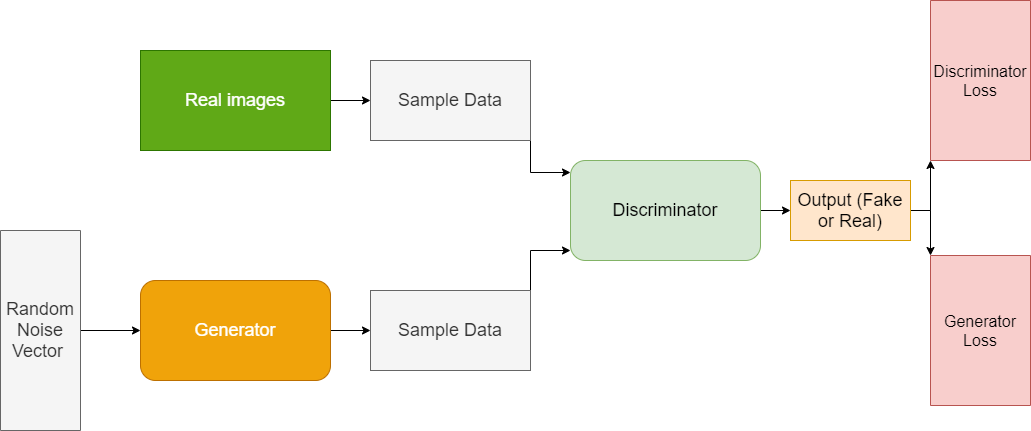
Figure 1 - Schéma de fonctionnement d’un réseau antagoniste génératif
Les réseaux génératifs antagonistes (GAN) [1] forment une famille de réseaux de neurones génératifs capables de capturer la distribution des données.
Les GAN se composent de deux réseaux séparés :
Les deux modèles sont entraînés en opposition : le discriminateur apprend à distinguer les données issues de la véritable distribution de celles produites artificiellement par le générateur, tandis que le générateur apprend à tromper le discriminateur.
Du point de vue du discriminateur, on cherche à maximiser la fonction objectif qui permet de séparer les valeurs du logit de sortie pour les données réelles (sortie positive) des valeurs du logit pour les données synthétiques (sortie négative) :
avec .
Tandis que, pour le générateur, nous cherchons à minimiser cette quantité. Comme n’intervient que dans le terme de droite, la fonction objectif à minimiser pour le générateur est :
Au bout du compte, l’optimisation du GAN est donc un jeu minimax défini par la fonction objectif :
(1) [3].
Le générateur transforme un bruit en une observation synthétique , c’est-à-dire que l’on tire au hasard un code latent selon une loi normale dans l’espace de dimension . On pourrait choisir d’autres lois de probabilité (par exemple, une distribution uniforme) mais la loi normale est la plus commune.
L’objectif de est d’apprendre à tromper le discriminateur, c’est-à-dire produire des observations telles que et donc que la distribution des données synthétiques soit indifférenciable des données réelles.
Le discriminateur classe les observations
en deux catégories : réelles ou artificielles. Sa sortie est constitué d’un seul neurone dont la fonction d’activation est une sigmoïde :
qui prend ses valeurs dans l’intervalle
. Par convention, on étiquette les données réelles avec un score de 1 et les données synthétiques avec un score de 0.
L’optimisation du générateur et du discriminateur s’effectue en alternance. Une itération de l’algorithme d’apprentissage du GAN peut se décrire de la façon suivante :
Considérons désormais un générateur fixé. On optimise alors uniquement le discriminateur pour réaliser la classification binaire des observations entre réelles et synthétiques. La fonction objectif à optimiser est donc :
Cette fonction objectif admet pour maximum :
La valeur optimale de est donc :
On peut montrer que :
où
est la divergence de Jensen-Shannon, définie par la formule suivante :
[4].
L’optimisation du générateur revient donc à minimiser la divergence Jensen-Shannon entre la distribution des données réelles et la distribution des données synthétiques .
Dans les réseaux antagonistes, le discriminateur fait office de test permettant de juger si les deux distributions (réelle et générée par le générateur ) sont statistiquement différentes. Autrement dit définit une mesure de distance implicite entre les deux distributions. Le discriminateur tente de maximiser cette distance tandis que le générateur s’efforce de la réduire [3].
Il existe de nombreuses applications de génération de données en utilisant des GANs et il existe également plusieurs variantes de ce réseau, des versions améliorées ou bien adaptées à des cas bien précis.
Avec un Conditional GAN, ou cGan, il est possible d’envoyer des informations plus précises, appelées labels de classe, au générateur et au discriminateur pour cadrer leur production de données. Ces informations vont permettre de préciser les données produites par le générateur et le discriminateur, afin qu’ils arrivent plus rapidement au résultat voulu. Les labels vont orienter la production du générateur pour lui permettre de générer des informations plus précises.
Au lieu de produire des images de vêtements, par exemple, il produira des images de pantalons, de vestes, ou de chaussettes selon le label qu’on lui fournit. Du côté du discriminateur, les labels vont permettre au réseau de mieux distinguer les images réelles des fausses images que va lui fournir le générateur. Il gagnera donc en efficacité [5]. Le Conditional Generative Adversarial Network peut-être très utile dans les cas suivants :
La traduction d’image à image : les cGAN permettent notamment de faire évoluer des images en prenant en considération des infos additionnelles, les labels. Le cGan a permis le développement de la méthode Pix2Pix dont certaines applications permettent la reconstruction d’objets à partir des bords, la synthèse de photos à partir de cartes d’étiquettes et la colorisation d’images [6].
La création d’images à partir de texte : grâce au cGAN, il est possible de créer des photos de haute qualité sur la base d’un texte. L’utilisation d’un texte, et la richesse de son vocabulaire, permet de créer des images de synthèse beaucoup plus précises.
La génération de vidéo : en vidéo, le cGan peut également prédire les futures images d’une vidéo sur base d’une sélection d’images précédentes.
La génération de visages : le cGANs peut-être utilisé pour générer des images de visages avec des attributs particuliers, par exemple la couleur des cheveux ou des yeux [7].
Pour ce qui est de la partie formelle, nous disposons parfois d’une information additionnelle qui vient s’ajouter à l’observation . Cette information peut être l’appartenance à une classe (« chat » ou « chien »), la hauteur d’un accord ou encore les valeurs précédentes d’une séquence. Afin de structurer l’espace latent et de pouvoir contrôler plus finement la génération, il peut être intéressant de conditionner les distributions à cette information.
Concrètement, cela revient donc à s’intéresser à et , c’est-à-dire en remplaçant dans l’équation (1) au jeu minimax:
(2).
Cette formulation donne lieu au conditional GAN [8]. En pratique, il suffit de modifier l’architecture du GAN de sorte que:
L’objectif originel du Wasserstein GAN est d’améliorer la stabilité d’apprentissage, de se débarasser de certains problèmes tout en apportant de sérieuses améliorations permettant de faciliter le débuggage et la recherche d’hyper-paramètres [9, 10].
Comparé au discriminant du GAN originel, le Wasserstein GAN offre un meilleur signal d’apprentissage au générateur. Ceci permet à l’entraînement d’être plus stable lorsque le générateur traite des données dans des espaces de très grandes dimensions.
Comme nous venons de le voir, la formulation du GAN introduite par Goodfellow et al. [1] revient implicitement à minimiser une divergence entre la distribution des données réelles et la distribution approchée par le générateur du GAN. Toutefois, la divergence de Jensen-Shannon [4] hérite des inconvénients de la divergence de Kullback-Leibler [11, 12] dont elle est dérivée:
Mais les divergences ne sont pas les seules fonctions capables de caractériser la dissimilarité entre deux distributions. Il existe au moins deux autres fonctions pouvant servir de distances entre probabilités: la variation totale (dont nous ne parlerons pas) et la distance de Wasserstein (ou Earth-Mover distance) [13]. La distance de Wasserstein entre deux distributions réelles et fausses est obtenue par:
(3) avec
l’ensemble de toutes les distributions jointes
dont les marginales sont égales à
et
.
Intuitivement, la distribution jointe représente la « masse » qui est transportée de chaque point vers chaque point , de sorte que la distribution soit transformée en la distribution . La distance de Wasserstein cherche alors le transport qui minimise le coût de cette transformation. Il s’agit ainsi du transport optimal entre et .
Cette distance est intéressante à deux titres. D’une part, elle croît linéairement avec la distance entre les moyennes des distributions, même si et sont disjointes. D’autre part, elle est continue et même différentiable par rapport aux paramètres de lorsque cette distribution est supposée gaussienne. Cela rend la distance de Wasserstein appropriée pour une optimisation par descente de gradient, par exemple [14].
Cependant, pour trouver le minimum de l’équation (3), il faudrait pouvoir parcourir toutes les distributions conjointes , ce qui est insoluble. Toutefois, la dualité de la distance de Kantorovich-Rubinstein (ou Wasserstein) nous donne une autre façon de la calculer :
(4) pour
appartenant à l’ensemble des fonctions K-lipschitziennes, c’est-à-dire vérifiant la condition:
Qu’est-ce que ceci signifie pour les GAN ? Dans notre cas, est la distribution des données réelles ( ) et est la distribution des données synthétiques ( ). Notre idée est de chercher les poids du discriminateur qui maximise une certaine distance entre et , et les poids du générateur qui minimise cette même distance.
Supposons que notre discriminateur soit contraint au sous-ensemble des fonctions K-lipschitziennes. Alors, d’après (4), une façon de calculer la distance de Wasserstein entre et est de calculer:
(5).
Cette quantité peut être approchée via une estimation sur un batch de observations :
Nous pouvons alors définir le Wasserstein GAN [9] comme le GAN optimisant le jeu minimax :
sous réserve que le discriminateur
soit restreint au cas K-lipschitzien [3].
En Décembre 2018, les chercheurs de Nvidia distribuent une pré-impression d’un logiciel d’accompagnement présentant StyleGAN, un Generative Adversarial Network capable de produire un nombre illimité de faux portraits humains. La plupart de ces derniers étant très convaincants.
En février 2019, l'ingénieur Uber Phillip Wang utilise le logiciel pour créer This Person Does Not Exist, qui crée un nouveau visage à chaque rechargement de page Web [15, 16]. Wang lui-même a exprimé son étonnement, compte tenu du fait que les êtres humains ont évolué pour comprendre spécifiquement les visages humains, de voir que StyleGAN peut néanmoins, de manière compétitive, « séparer toutes les caractéristiques pertinentes (des visages humains) et les recomposer de manière cohérente » [17].
De même, deux professeurs de l'école d'information de l'Université de Washington ont utilisé StyleGAN pour créer Which Face Is Real, qui mettait les visiteurs au défi de faire la différence entre un faux et un vrai visage côte à côte [16]. La faculté a déclaré que l'intention était « d'éduquer le public » sur l'existence de cette technologie afin qu'il puisse s'en méfier, « tout comme finalement la plupart des gens ont été informés que vous pouviez Photoshoper une image » [18].
StyleGAN est une architecture de GAN qui introduit un espace latent intermédiaire, entre l’espace latent du bruit et l’espace des images . Cet espace, noté , est appelé espace des styles [19].
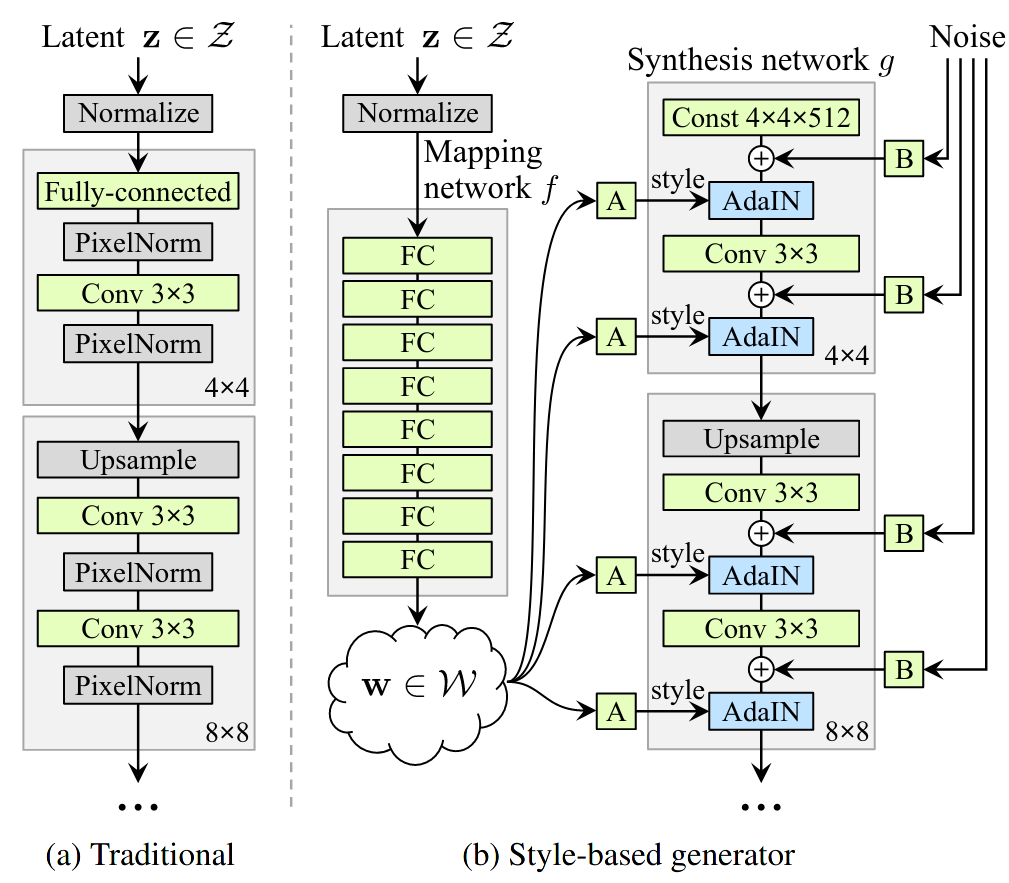
Figure 2 - Comparaison de l’architecture habituelle du générateur dans un GAN convolutif (à gauche) et de l’architecture du générateur dans StyleGAN [19].
Le générateur de StyleGAN introduit un mapping network, un perceptron multi-couche qui transforme le bruit initial en un vecteur de style . Dans le schéma, A désigne une transformation affine apprise et B est une multiplication terme à terme avec un vecteur de mise à l’échelle.
En pratique, StyleGAN utilise un espace de style de dimension 512. Ce vecteur de style est ensuite injecté à chaque couche du générateur à travers l’opération AdaIN, ou Adaptive Instance Normalization [20]. AdaIN est une couche de normalisation qui applique une transformation affine :
où
avec
une transformation affine apprise pour la couche considérée,
désigne la moyenne de
et
sa variance. Les vecteurs
sont appelés les styles correspondant au vecteur latent
.
L’avantage de l’espace par rapport à l’espace latent est qu’il est obtenu par une transformation non-linéaire et ne suit donc pas forcément une distribution gaussienne. Cela permet ainsi de mieux capter la structure de la distribution des images, qui est généralement fortement multi-modale. En pratique, pour renforcer le rôle des « styles », on combine les vecteurs obtenus pour différents durant l’entraînement. Ainsi, les styles seront aléatoirement injectés dans le générateur à la place de et inversement [3].
