Fonctionnement du générateur et du discriminateur
Un réseau antagoniste génératif (GAN) se compose de deux parties :
- Le générateur apprend à générer des données plausibles. Les instances générées deviennent des exemples d’entraînement négatifs pour le discriminateur.
- Le discriminateur apprend à distinguer les données fictives des données réelles. Il pénalise le générateur pour avoir produit des résultats impossibles à comprendre.
Lorsque l’entraînement commence, le générateur génère des données manifestement factices, et le discriminateur apprend rapidement à dire qu'il s'agit de fausses données. À mesure que l'entraînement progresse, le générateur réalise des images de plus en plus capables de tromper le discriminateur. Enfin, si l'entraînement du générateur fonctionne bien, le discriminateur peine à distinguer quelle image est authentique. Il commence à classer les fausses données comme étant réelles, et sa précision diminue.
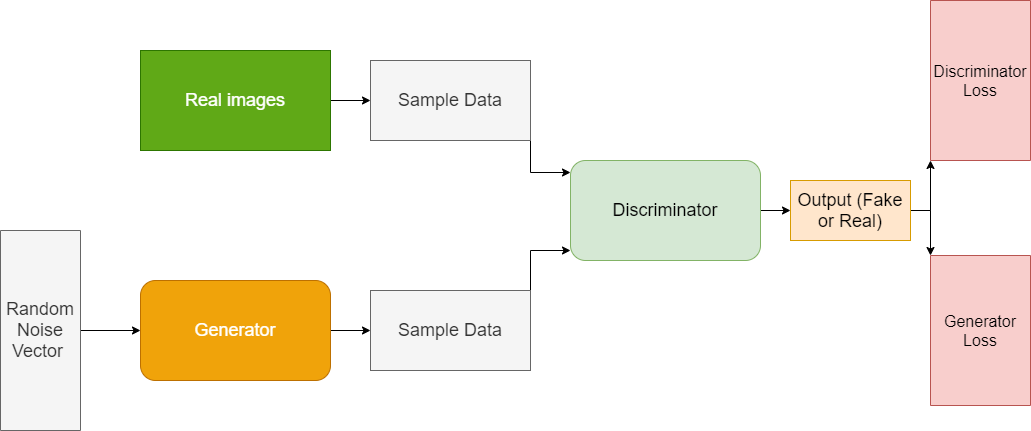
Figure 1 – Schéma de fonctionnement d’un réseau antagoniste génératif
Le générateur et le discriminateur sont des réseaux de neurones. La sortie du générateur est directement connectée à l'entrée du discriminateur. Grâce à la rétro-propagation, la classification du discriminateur fournit un signal permettant au générateur de mettre à jour ses poids [1].
Explorons en détail les éléments de ce système.
1) Générateur
Le rôle principal du générateur est de créer de nouvelles données. Initialement, la donnée est souvent générée à l’aide d’un facteur aléatoire, puisque le générateur débute sans vraiment connaître les données de départ. Au fil du temps, pendant l’entraînement du GAN, le générateur apprend à produire des données similaires aux données initiales.
En entrée, le générateur prend un vecteur de bruit aléatoire, typiquement échantillonné à partir d’une distribution normale ou uniforme. Ce vecteur sert alors de point de départ pour la génération de données.
Puis, en sortie, il va créer de nouvelles données factices. Dans le cas d’un GAN employé pour la génération d’images, la sortie sera alors une image. La donnée est transmise au discriminateur qui sera ensuite juge de déterminer si elle est authentique ou non.
a) Architecture
L’architecture peut varier, les générateurs de plusieurs GANs populaires ( comme DCGAN par exemple ) sont construits en utilisant des couches convolutives transposées ( souvent appelées couches de « déconvolution », même si le terme est inapproprié ), ce qui aide à sur-échantillonner le vecteur de bruit permettant de produire une image. Le générateur consiste généralement en une séquence des composants suivants :
- Couche d’entrée : Le générateur démarre avec une couche de départ prenant un vecteur de bruit aléatoire, souvent échantillonné à partir d’une distribution normale ou uniforme.
- Couches complètement connectées : Tôt dans le réseau, les couches complètement connectées peuvent être utilisées pour transformer le vecteur de bruit initial en une forme appropriée pour le traitement ultérieur.
- Normalisation de Batch : Cette technique est parfois utilisée entre les couches pour stabiliser l’apprentissage en normalisant les entrées d’une couche. Cela aide à résoudre certains problèmes comme le mode collapse mais aussi à converger plus rapidement.
- Fonctions d’activation : Les fonctions ReLU et Leaky ReLU [2, 3] sont régulièrement utilisées en tant que fonction d’activation du générateur. Elles introduisent une non-linéarité au modèle, lui permettant de générer des données complexes.
- Couches convolutives transposées : Ces couches sont fondamentales au générateur. Elles permettent de sur-échantillonner les entrées des couches précédentes à une dimension spatiale plus élevée, en faisant précisément l’inverse de ce que ferait une couche convolutive au sein d’un CNN [4].
- Couches de réorganisation : Ces couches sont utilisées pour réorganiser la donnée dans le format désiré, plus particulièrement lorsque des images sont générées.
- Couche de sortie : La couche finale utilise souvent une fonction d’activation tangente hyperbolique ou sigmoïde, cela dépend de la nature de la donnée à générer. Pour la génération d’image, la tangente hyperbolique est souvent utilisée pour afficher la valeur des pixels sur une plage normalisée.
- Entraînement : Durant l’entraînement, le générateur apprend en continue à produire des données ayant pour objectif de tromper le discriminateur. Le générateur met à jour ses poids selon le retour du discriminateur, en affinant sa capacité à créer des données factices [5].
b) Entraînement
Durant l’entraînement, le générateur essaie de tromper le discriminateur en produisant des données qui seront impossible à discerner des originelles. Le générateur met ensuite à jour ses poids en considérant le retour du discriminateur. S’il distingue correctement que l’image générée est fausse, alors le générateur ajuste ses poids, de manière à générer des données plus convaincantes lors de la prochaine itération.
Ce processus peut être perçu comme une sorte de « jeu » où le générateur essaie constamment de s’améliorer, visant à produire à terme des données presque indistingables des originelles. Cependant, certains problèmes peuvent tout de même apparaître lors de l’entraînement :
- Mode Collapse : C’est une situation où le générateur produit une diversité limitée de données, même en étant entraîné à partir de données variées. D’une certaine manière, c’est un peu comme si le générateur avait repéré un genre de données factices trompant le discriminateur et ne produit alors que cela. Ce problème peut être atténué en introduisant des techniques de régularisation, diversity-promoting loss functions, ou bien même en utilisant différentes méthodes d’entraînement comme la minibatch discrimination.
- Instabilité d’entraînement : Les GANs, en général, sont reconnus comme étant difficiles à entraîner, avec le générateur dont l’entraînement peut se montrer difficile. C’est le cas puisque l’optimisation est large en impliquant deux modèles ( générateur et discriminateur ) entraînés simultanément avec des paramètres dynamiques. Ce problème peut être réduit en adoptant certaines techniques comme la pénalité du gradient, en utilisant des planificateurs de taux d’apprentissage ( learning rate schedulers ) ou bien même en adoptant des architectures de GAN spécifiques et donc plus stables [5].
2) Discriminateur
Le rôle du discriminateur est de distinguer les vraies des fausses informations. Dans le cas des GANs, le discriminateur essaie de différencier les images authentiques des fausses générées par le générateur.
En entrée, il prend des échantillons de données, authentiques ou générées. Puis, en sortie, il renvoie une valeur scalaire comprise entre 0 et 1, représentant la probabilité que l’entrée soit réelle. Une valeur proche de 1 signifie que l’échantillon est probablement authentique, tandis qu’une valeur proche de 0 suggère qu’il est probablement faux.
a) Architecture
L’architecture ( le nombre de couches, le type de couches, etc. ) peut varier très largement suivant l’objectif ainsi que le jeu de données initial. En l’occurence, pour les images, les discriminateurs utilisent très souvent des réseaux de neurones convolutifs (CNNs).
L’architecture des discriminateurs est souvent très similaire aux traditionnels réseaux de neurones convolutifs (CNNs), mais avec quelques ajustements. Cela consiste généralement en la séquence des éléments suivants :
-
Couches convolutives : Ces couches sont fondamentales pour le traitement des images et l’extraction de leurs caractéristiques. Le nombre de couches convolutives peut varier suivant la complexité des données.
-
Normalisation de Batch : Cette technique est parfois utilisée entre les couches pour stabiliser l’apprentissage en normalisant les entrées d’une couche.
-
Fonctions d’activation : La fonction Leaky ReLU [6, 7] est régulièrement utilisée en tant que fonction d’activation du discriminateur. Elle permet d’obtenir un petit gradient lorsque l’unité n’est pas activée, ce qui peut aider à maintenir le débit du gradient lors de l’entraînement.
-
Pooling layers : Les neurones de mise en commun des sorties dites de « pooling » permettant de réduire les dimensions spatiales progressivement des données d’entrée.
-
Fully Connected Layers : Au bout du réseau, les « couches entièrement connectées » sont utilisées pour traiter les caractéristiques extraites par les couches convolutives, aboutissant à une couche de sortie finale.
-
Couche de sortie : La dernière couche est généralement un seul et unique neurone avec une fonction d’activation sigmoïde permettant d’en dégager une valeur de probabilité.
Évidemment, cette architecture peut varier largement suivant les différents problèmes et jeux de données. Les différences principales entre l’architecture d’un Réseau Neuronal Convolutif, ou CNN, et celle d’un discriminateur de GAN sont les suivantes :
-
Fonction de perte : Les CNNs utilisent plusieurs fonctions de perte différentes, tandis que le discriminateur du GAN utilise toujours l’entropie croisée binaire puisqu'il n’a que deux résultats possibles : authentique ou factice.
-
Boucle de rétroaction : Au sein des CNNs, il n’y a pas de boucle de rétroaction, le réseau ne peut pas se développer en parallèle à un autre et est entraîné isolément en utilisant un jeu de données doté d’étiquettes. Tandis que le discriminateur du GAN se développe en tandem avec le générateur du réseau, le discriminateur fait un retour au générateur, lui permettant d’améliorer sa capacité à créer des images pertinentes.
-
Fonction d’activation de sortie : Suivant la tâche, les CNNs peuvent être amenés à utiliser la fonction softmax [8], tandis que le discriminateur du GAN utilise typiquement la fonction sigmoïde dans la couche de sortie. Ceci nous renvoie alors une probabilité permettant de distinguer si l’image est authentique ou factice.
-
Profondeur et complexité : Le discriminateur du GAN est souvent plus simple et moins profond que les CNNs conventionnels. Cependant, évidemment, la complexité dépend de l’architecture du GAN spécifiquement utilisé, ainsi que du jeu de données utilisé [5].
b) Entraînement
Durant l’entraînement, le discriminateur met à jour ses poids de la façon suivante : lorsque des données authentiques lui sont montrées, il doit être entraîné de manière à renvoyer des valeurs proches de 1. Tandis que, lorsque des données factices lui sont montrées, il doit être entraîné de sorte à renvoyer des valeurs proches de 0.
Cependant certains défis restent d’actualité comme les suivants :
-
Discriminateur surpuissant : Si le discriminateur devient trop fort trop rapidement, il pourrait alors toujours réponde de façon bien trop sûr de lui. C’est-à-dire renvoyer soit 0 soit 1 pour n’importe quelle entrée, rendant alors l’apprentissage pour le générateur très difficile. Ce problème peut-être atténué en implémentant différentes techniques comme le label smoothing, le feature matching ou bien en ralentissant délibérément la vitesse d’apprentissage du discriminateur.
-
Discriminateur faible : A l’opposé, si le discriminateur est trop faible, le générateur pourrait ne jamais obtenir de retour constructif pour s’améliorer. L’équilibre entre le générateur et le discriminateur durant l’entraînement est crucial pour assurer le succès du GAN. Ce problème peut être réduit en améliorant la capacité du discriminateur, en ajustant son débit d’apprentissage, ou bien en utilisant des architectures permettant d’améliorer la puissance du discriminateur [5].
- [1] Google, « Overview of GAN Structure », 2022. Google for developers.
- [2] Brownlee Jason, A Gentle Introduction to the Rectified Linear Unit (ReLU)", 2020. Machine Learning Mastery.
- [3] Liu Danqing, "A Practical Guide to ReLU", 2017. Medium.
- [4] George Lawton, "CNN vs. GAN : How are they different?", 2023. TechTarget, AI technologies.
- [5] Marco Del Pra, « Generative Adversarial Networks », 2023. Medium.
- [6] Brownlee Jason, "A Gentle Introduction to the Rectified Linear Unit (ReLU)", 2020. Machine Learning Mastery.
- [7] Liu Danqing, "A Practical Guide to ReLU", 2017. Medium.
- [8] Yusaku Sako, “Is the term “softmax” driving you nuts?”, 2018. Medium.
